Ladder Logic 303: PLC Forensics
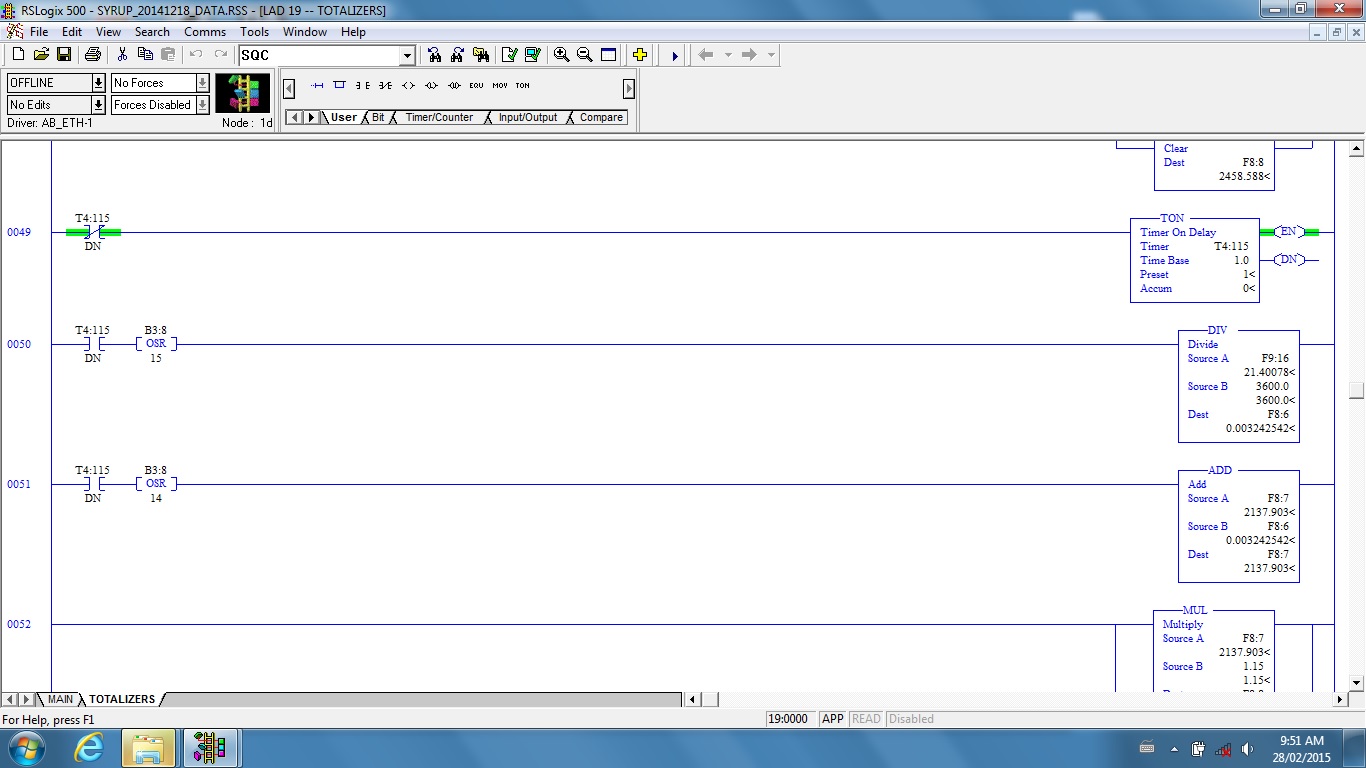
Today’s topic involves a project I have been working on over the last few months. The project consists of adding process equipment including tanks, pumps, valves and instrumentation to an existing system… while it is running.
Because production runs 24 hours a day, 6 days a week most of the work needs to be done while online with the processor. I can do a download on Sundays since that is cleaning day, but other than that changes are made incrementally.
The platform is an Allen-Bradley SLC 5/05 with an RSView32 SCADA system. It was installed in the early 2000’s by a large process integrator out of Europe via a Brazilian branch. The original PLC template took some getting used to, but is pretty well written and documented overall. There are 160+ data registers and more than 120 separate subroutines though which took some deciphering to figure out what was going on.
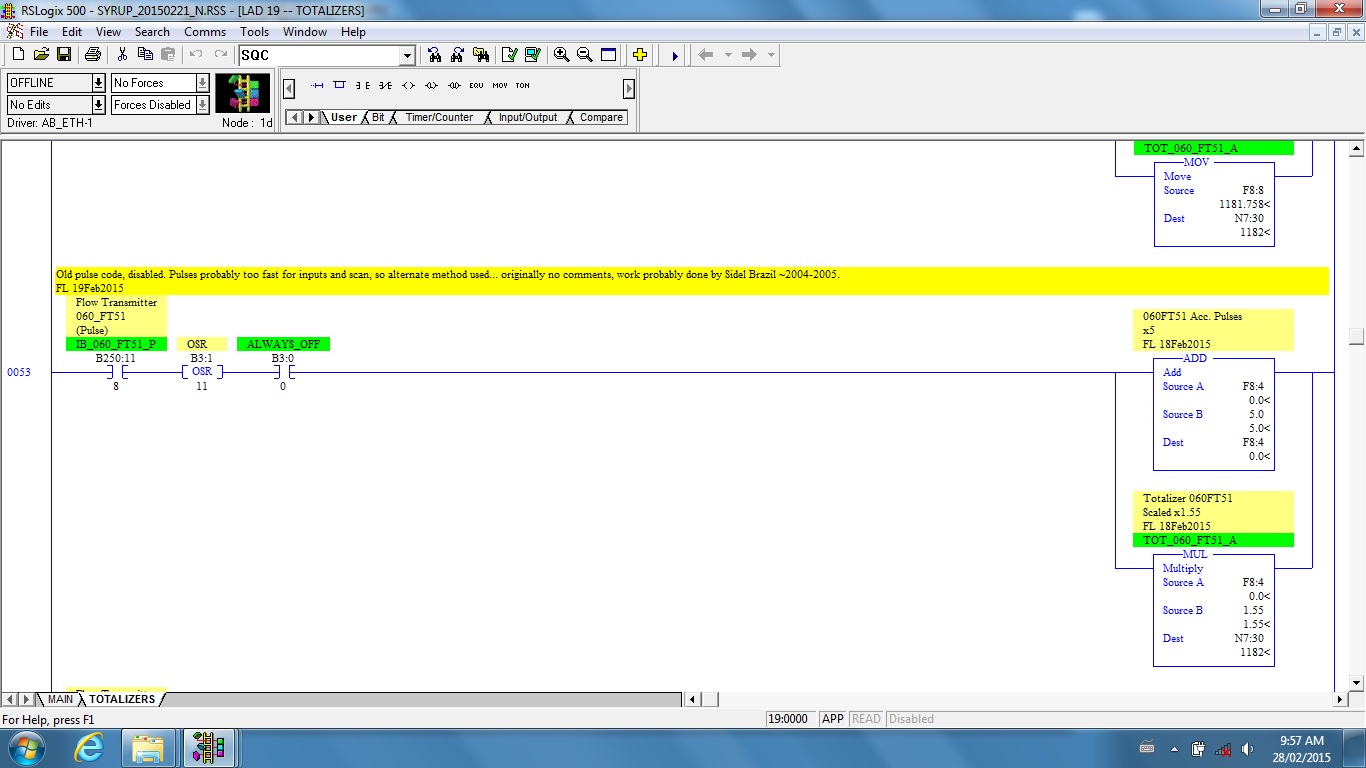
While most of the program is commented fairly well, there are sections with no documentation at all. The picture above shows a section of code I’d like to discuss today.
Much of the work I am doing involves simply duplicating existing code for new subsections. For instance, if I need to put in a new tank I simply duplicate code for an existing tank and change the I/O and other data addresses. Some code needs to be customized, but as long as things are labeled properly the work is fairly straightforward, though tedious.
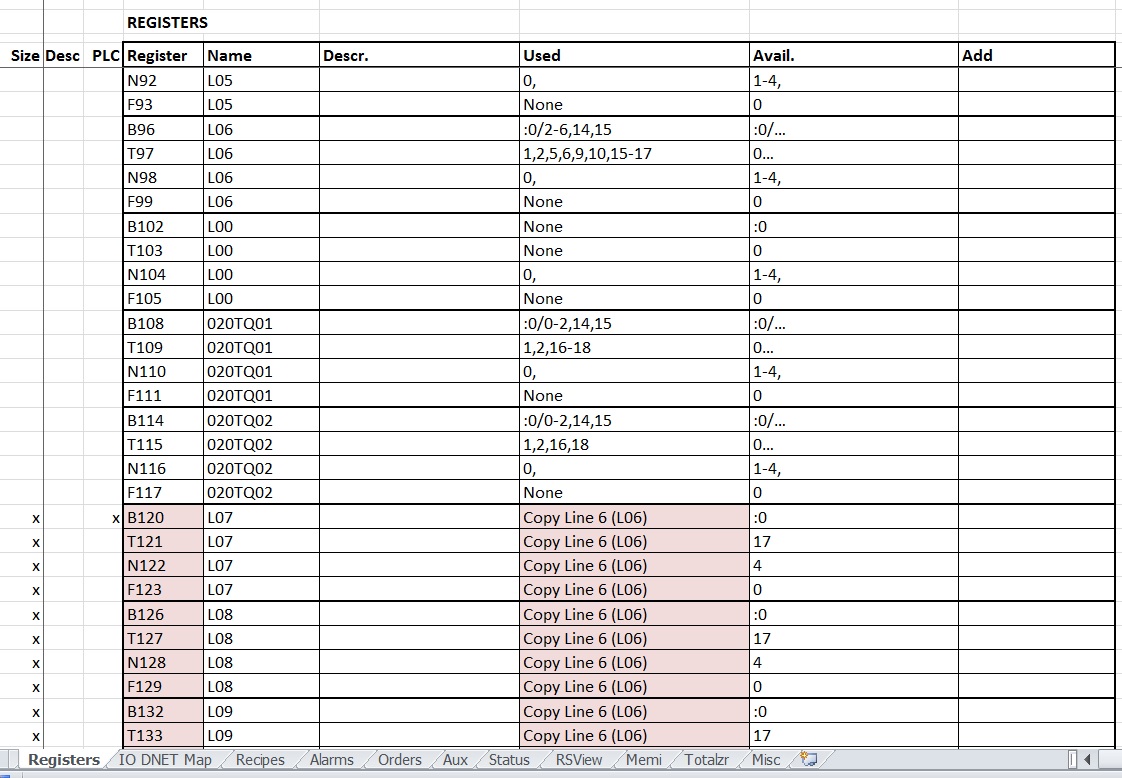
This picture shows part of the spreadsheet I started back during the design phase of the project. It illustrates one of the points I want to make here: before beginning modification of code you need to figure out the layout of the existing system. Most programmers organize code systematically, so determining how they laid out the original program is important if you want to stay true to the template. Some programmers think they have a better way to code than the original programmer, and sometimes that may be true, but if the original program was written by a professional it is really doing a disservice to future programmers to try and insert a different method into an existing program. It simply complicates things.
This spreadsheet has grown as the project progressed. You can see by the tabs at the bottom of the spreadsheet that I needed to keep track of a lot of different things. You can think of this spreadsheet as auxiliary memory; any time I needed to analyze a section of code or organize processor memory I added a worksheet.
When it came time to add flow transducers to the new equipment I ran into the code at the top of this post. Since this was not documented (no comments) I assumed it had been added later. After talking to some of the people who had been at the plant for a long time I discovered that indeed, some of the original equipment hadn’t worked correctly so some of the technicians had come back out and modified the program.
The programmer who did the modifications may have commented the program, but for whatever reason the plant engineers didn’t have a copy with comments. Trying to read through code without comments is nearly useless, so the next step was to comment the code.
Usually I start out by labeling things I can find from the electrical drawings. In this case each flow transducer had one analog and one digital input each, so I started there. I also used the addresses on the SCADA screen to determine which were the scaled values displayed. Since there was a flow rate in liters/hour and a totalizer for liters I was able to label more registers. The rest of the calculated values and timers were fairly easy, I just named them after whatever they did.
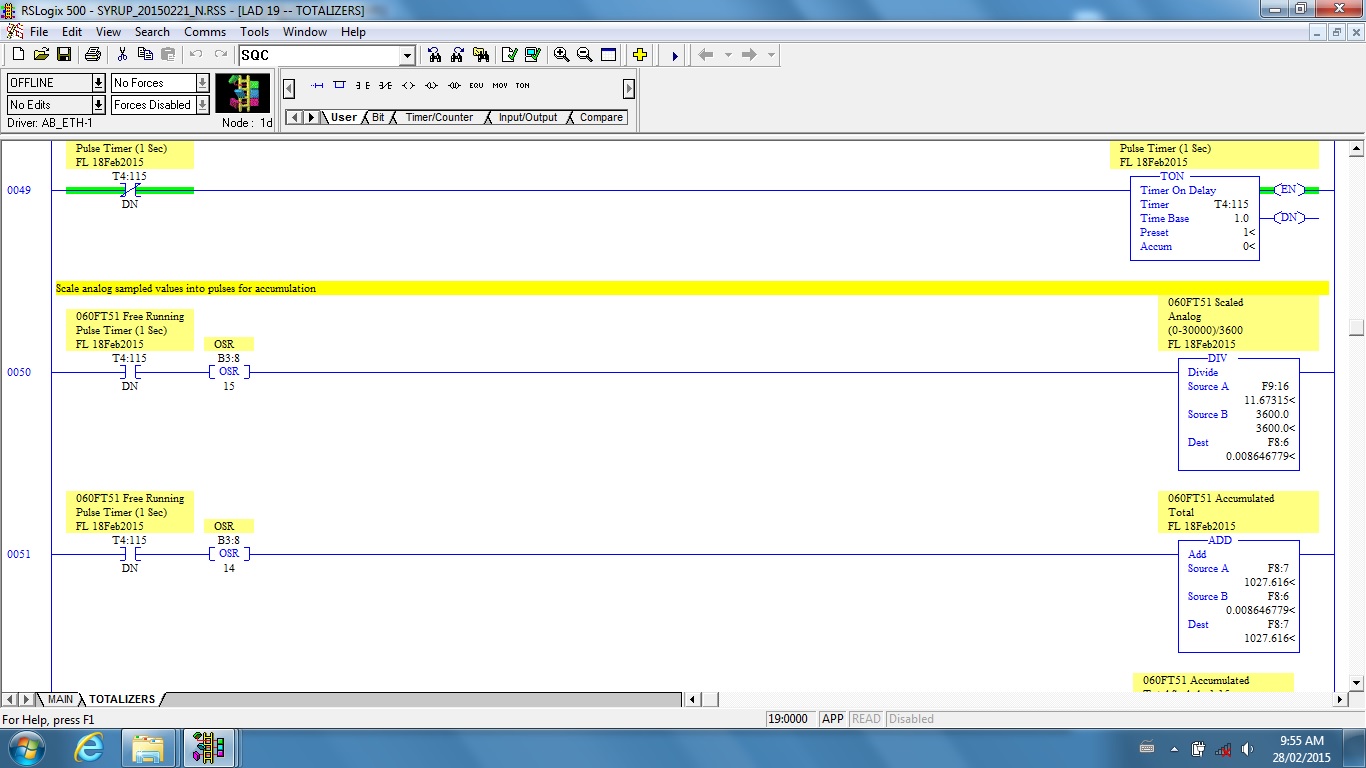
When I had finished labeling the registers this is what it looked like. A few things to notice: I even label OSRs, or oneshots. The main reason for this is to help determine whether a tag has been used before. Yes, you can always use a cross reference, but this is faster and also tells whether a bit was assigned and then code was later deleted.
I also dated every undocumented tag and added my initials. This was so that it could be easily determined that the data was not from the original program nor from my new additions. This also helps in future forensic examinations. I then added rung comments if it was not easily evident what the code was used for. This is for my own use as well as for future programmers.
After finishing the documentation I was able to read the code and make some interesting discoveries. One thing was that there were 7 different transducers and the code had been written in at least 4 different ways. This implies that there may have been at least a couple of different programmers working on this problem.
The most important discovery was that the digital inputs from most of the transducers had been disabled, implying they didn’t work. Instead, the analog flow had been taken in one-second chunks and turned into an artificial pulse count. Reasons for this include the long scan time of the processor (80ms or more) which makes it easy to miss pulses, and the fact that the I/O was over DeviceNet, which added further processing time.
The problem with doing this is that inaccuracies are introduced into the calculations by variations in ambient noise (cancelled by a constant offset) and all of the transducers being scaled differently. Most of the values were calculated by making guesses at values until the tank fill actual volumes closely matched the calculated volume.
An option to make the pulses work would be to put in a couple of High Speed Counter cards and run the transducer pulses into them. This gets around the scan time issues by separating the accumulation from the code scan. Unfortunately this would take a lot of down time, which the customer doesn’t have. So at this point the new transducers will need to use this same analog method, though I will probably be able to make it more accurate.
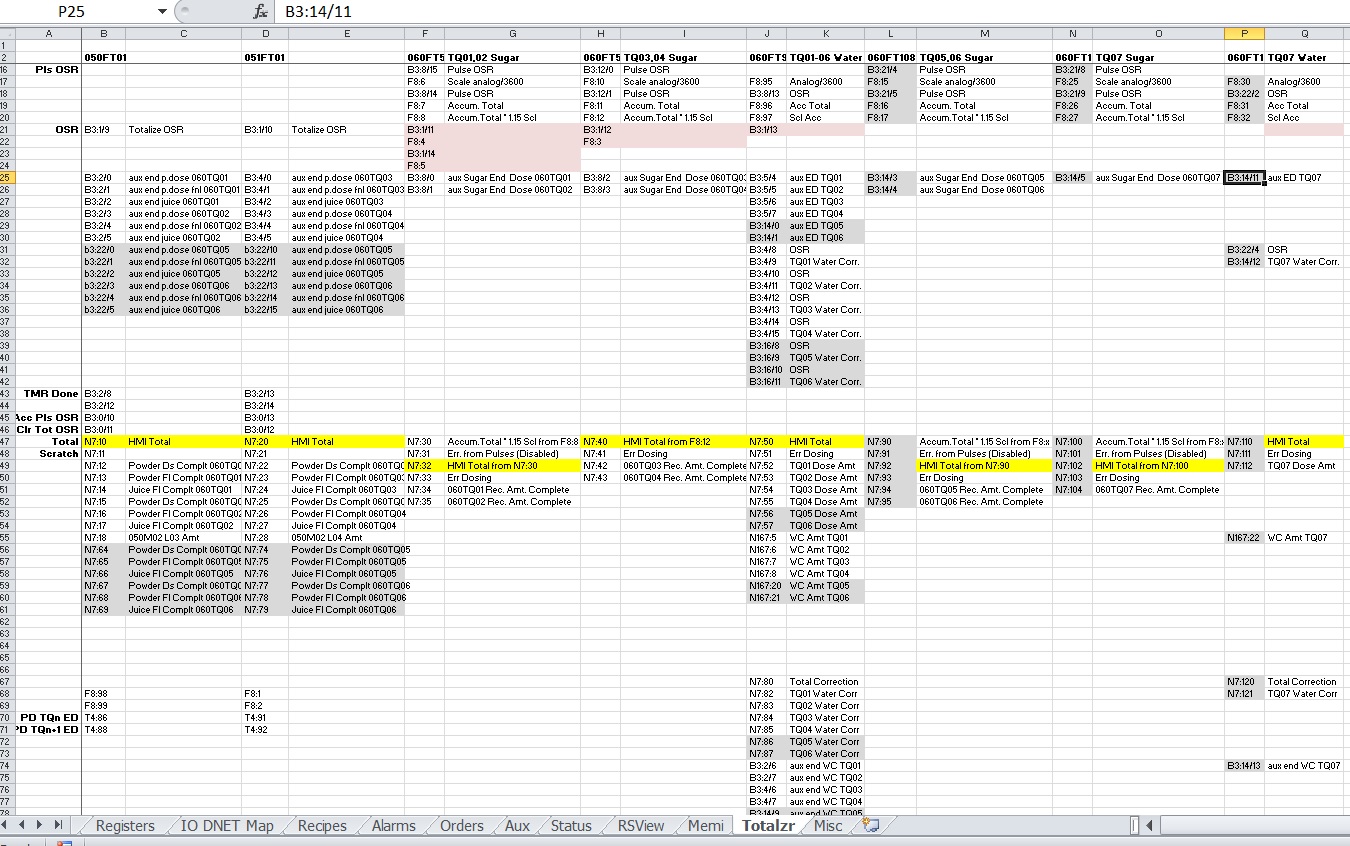
This is the totalizer page of the spreadsheet. As you can see, the data columns listing the registers and values don’t match, even between similar transducers used for the same purpose. I cleaned up some of the existing code, but left the disabled part for future programmers’ information. I then duplicated the cleanest coded transducer to my new ones. As you can see from the list of data points in each column, there is a lot that can go into a simple analog transducer’s code.
This is where I left the comment for future forensic investigators who may want to know why the code was written this way.
Unfortunately you don’t always get to write you own program using your own techniques from scratch. Sometimes you need to use someone else’s methods, and those methods may not be your favorite way. Still, if a big complex program has been doing its job for years and maintenance people are used to it, the best course is to use the same methodology. This can take a lot of up-front planning and some forensic discovery, but is usually the best course.
I would also caution would-be programmers to be very careful about doing this kind of thing online as I am. Changes need to be made systematically and thought out very carefully so as not to disrupt production. So for those who are in management and think this might be an option for your plant or line to save some money, there are not a lot of people who have the necessary experience to do this. And it does take a lot of time, there really are no short cuts.
At the same time, it can be kind of fun!

Electrical Engineer and business owner from the Nashville, Tennessee area. I also play music, Chess and Go.
I have made it a practice when I am changing a program online to isolate the changes that I make by including toggleble bits in each rung that I am adding. In RSLogix 5000 I will create a new Boolean tag labeled something such as Disable_Toggle_Bit. In RSLogix 5 or RSLogix 500, I will use an unused Binary or Integer bit. I will give it a symbol to make it easier to search for. I normally use the same bit for all of the changes that I have made.
If I am replacing an existing rung, I will use an XIC contact on the rung I am adding, and an XIO contact on the rung that I am replacing. This brings up the existing code as the default. When I am ready to test it, I toggle the bit and disable all of the rungs of the original code and implement all of the added rungs at once. If there are any problems or un intended consequences, I can revert to the original code by toggling the bit again. The better that you do your pre planning, the less likely you are to have any issues, but this practice has served me well so far.
There are times when I am only changing part of a rung. I will do the same thing by creating a branch around the part that I want to change ang put the new code on the branch with an XIC contact, and I include the XIO contact on the original branch.
I hope that this may be of some use to someone.